In geospatial queries, we often need to find all the points of interests (POIs) within a certain distance from an anchor point. In this post, we present a simple method that scales very well for billions of data points and implemented using plain SQL; so it can be deployed on a massive data processing systems like Redshift or Hive/SparkSQL on Hadoop without utilizing any geospatial support components such as PostGIS.
In order to efficiently search nearby points, one would need to do a database join intelligently so that only reasonably nearby points are considered. We do not want to compare geographical points in New York, when we only need to find nearby points in Los Angeles. An easy way to accomplish this is to limit the search to geographical coordinates in Los Angeles (i.e. Zoom into Los Angeles). We elaborate how we are using this heuristic to find nearby points with varying accuracy levels in the following sections.
Discussion on Heuristics:
When it comes to coordinates and geographical distances, a quick rule of thumb we typically use is as follows: approximately 100m geographical distance is denoted by the increment in coordinate at 3 decimal point precision. This wiki page provides distances measured and precision latitude/longitude coordinates. The discussion here is mainly focused on the coordinates of the mainland USA.
However, for accurate distance calculation on spherical earth, we need to use Haversine formula (elevations are ignored). This elaborate formula is accurate, but expensive, so we will show how to judiciously combine both methods to derive elegant scalable methods.
Let us illustrate our approach with points of interests stored on this table:
point_of_interest(poi_id int, latitude double, longitude double);
Given millions of point_of_interest, it is not scalable approach to compare against each point to find nearby points. However, we do know adjacent coordinates translate to adjacent places. For example, the following depicts four coordinate points with approximately 100 meters between them. This 100m distance is derived from 3 decimal points.

Let us say our goal is to find POIs that are within 100 meters of a given point (let us call it anchor point). One naive solution is to round the decimal points of coordinates to 3 digit precision and gather points of interests by joining POI table on those rounded coordinate values.
SELECT poi_id FROM point_of_interest as P
WHERE ROUND(anchor.latitude,3)=ROUND(P.latitude,3)
AND ROUND(anchor.longitude,3)=ROUND(P.longitude,3)
In this example, one may use rounded coordinates as an indexing column or as distribution key in NoSQL stores such as Redshift, in order to obtain scalability to billions of data points.
As shown in the following picture, even though both POIs are within 100 meters of the anchor point, rounding the coordinates results in only one match, namely POI_1. We failed to detect POI_2 as within the range.
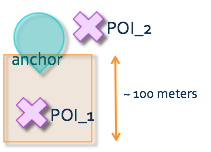
Imagine the anchor point falls on one of the corners of this box, and in such cases it can only detect POIs that fall within a single quadrant, leaving with us a solution that may miss 75% of POIs. Not acceptable.
Algorithms:
We now present two distinct scalable approaches for this problem.
- Using intermediate table consisting of POIs that are marked in adjacent boxes
We first create an intermediate points_of_interest table that duplicates and spreads each POI to the adjacent boxes, as seen below.

Now we can join the anchor point and POIs and then filter them by distance in meters measured using Haversine formula.
SELECT poi_id FROM intermediate_point_of_interest as P
WHERE ROUND(anchor.latitude,3)=ROUND(P.latitude,3)
AND ROUND(anchor.longitude,3)=ROUND(P.longitude,3)
AND Haversine_Distance_Formula(anchor,P) < 100
Here Haversine distance formula is calculated as follows:
distance = 111045* DEGREES(ACOS(COS(RADIANS(anchor.latitude))
* COS(RADIANS(poi.latitude))
* COS(RADIANS(anchor.longitude) - RADIANS(poi.longitude))
+ SIN(RADIANS(anchor.latitude))
* SIN(RADIANS(poi.latitude))))
Here, 111045 is the distance between latitudes in meters. For more explanation on this formula and alternate approaches to speeding up geospatial queries, please refer this blog post.
- Zoom into an arbitrarily sized box using rounding methodologies.
This methodology depends on the observation that if we were to use 1km boxes when looking for POIs within 100m, the probability the anchor point lies on the corner of 1km box is 100 times less than the probability of anchor point falling on the corner of 100m box. Motivated by this observation, we can round to 1km boxes when we look for 100m distance, as shown in the following query.
SELECT poi_id FROM point_of_interest as P
WHERE ROUND(anchor.latitude,2)=ROUND(P.latitude,2) -- 1km: round to 2
AND ROUND(anchor.longitude,2)=ROUND(P.longitude,2)
AND Haversine_Distance_Formula(anchor,P) < 100
This rounding methodology to chosen digits of precision will give us approximate distances in the multiples of 10. (100m, 1km, 10km etc). Taking motivation from kernel functions often used in SVM, we can obtain any arbitrary zoom distance by applying a formula before rounding the coordinates. For example, the following query zooms into a 500 meter box before applying Haversine distance filter for 125 meters.( Here, 500m is 5 times as big as 100m, so we divide each coordinate by 5 to make it equivalent to 100m before rounding off at three digit precision. )
SELECT poi_id FROM point_of_interest as P
WHERE ROUND(anchor.latitude/5,3)=ROUND(P.latitude/5,3)
AND ROUND(anchor.longitude/5,3)=ROUND(P.longitude/5,3)
AND Haversine_Distance_Formula(anchor,P) < 125
Conclusion:
In this post, we briefly presented a scalable and simple framework for identifying nearby geographical points solely by using SQL. By using plain SQL, this methodology can be applied in any of latest petabyte scale NoSQL database systems that typically do not have geographical tools/plug-ins.
For ease of presentation, we used a single anchor point to illustrate the examples, but in production, we have daily use cases where we need to join tables containing several thousand anchor points and tens of billions of other geographical points. Without these optimization techniques, it would be almost impossible and very expensive to do such geographical queries on scale and in a timely manner.